Dans cet article nous allons voir comment adapter notre workflow Data Science pour être conforme à l’AI Act.
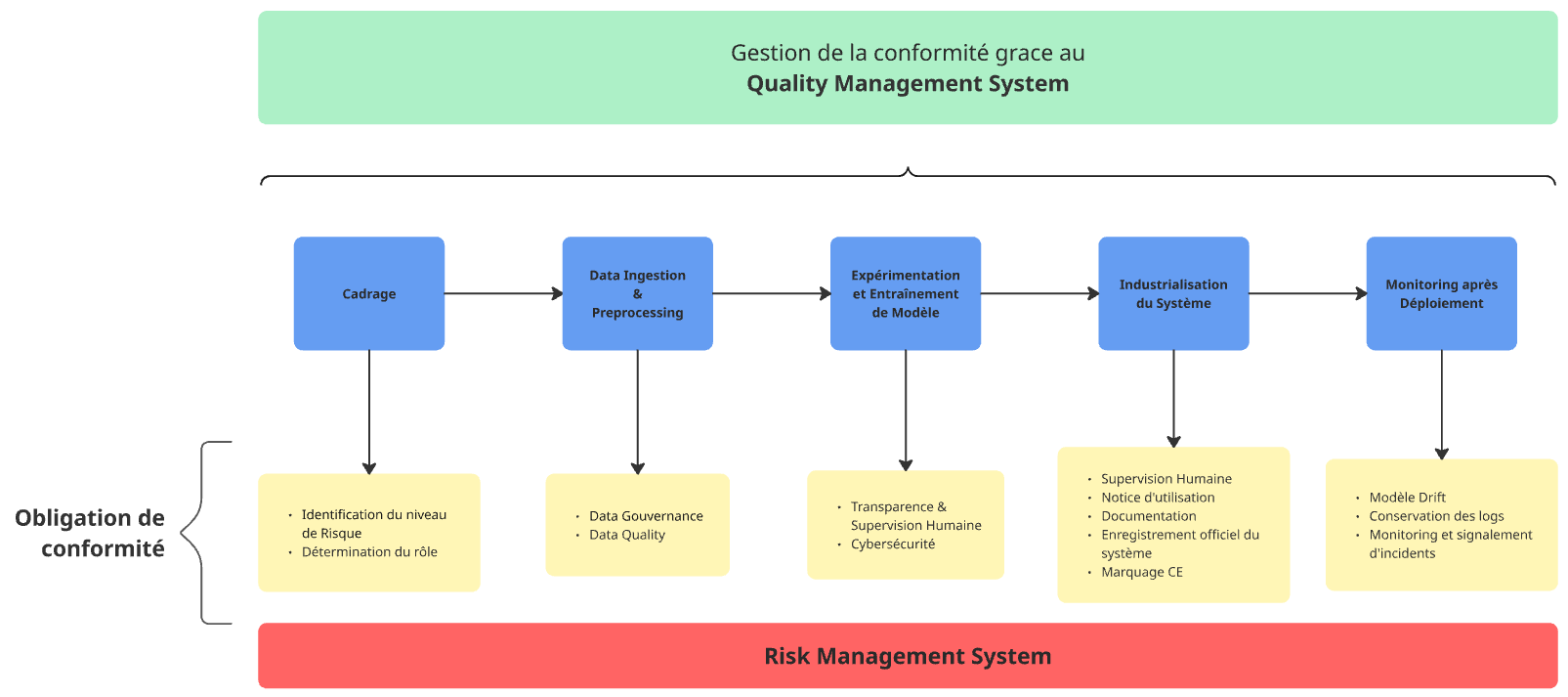
Nous suivrons chaque étape du cycle de développement d’un système d’IA, de la phase de cadrage initial jusqu’à l’industrialisation et au monitoring, en passant par la phase de preprocessing des données et d’entraînement des modèles.
Pour cela, nous nous mettrons dans la peau d’un provider travaillant sur un système d’IA classé à haut risque. En effet, en tant que Data Scientists, nous endossons souvent ce rôle dès lors que nous concevons, entraînons ou déployons des systèmes d’IA destinés à un usage interne ou à une commercialisation (voir Partie III de l’article précédent).
Il est important de garder à l’esprit que les obligations réglementaires et donc les méthodes de travail et les best practices qui en découlent varient selon la catégorie de risque du système. Si le système que vous développez est à risque faible ou modéré, le niveau d’exigence sera différent.
Enfin, pour garder une lecture claire, nous nous concentrerons ici sur le cas général. Pour autant, il existe de nombreuses situations particulières, par exemple l’utilisation d’un modèle pré-entraîné que l’on fine-tune. Dans un tel cas, il faudra à la fois vérifier la conformité du modèle initial pré-entraîné, puis appliquer toutes les exigences du provider sur le nouveau modèle fine-tuné.

I. Cadrage du projet
Comme pour tout projet d’IA, la première étape est celle du cadrage. Il s’agit de bien définir les besoins et contraintes métiers, les contraintes techniques, budgétaires, de cybersécurité, ainsi que les modalités d’usage du système par les utilisateurs finaux. Avec l’entrée en vigueur de l’AI Act, cette phase prend une dimension supplémentaire : l’évaluation du risque réglementaire et la détermination de notre rôle dans la chaîne de conformité.
1. Identification du niveau de risque du système
L’AI Act classe les systèmes d’IA selon leur niveau de risque. Comme ce niveau dépend du cas d’usage et non de la technologie employée, il peut (et doit) être défini dès la phase de cadrage. De plus, cette identification est cruciale pour connaître les obligations réglementaires à respecter dans la suite du développement du système.
2. Détermination de notre rôle vis-à-vis de l’AI Act
Pour rappel, l’AI Act définit plusieurs rôles réglementaires (provider, deployer, importer, distributeur). Il est fondamental d’identifier le rôle que l’on a, car ce rôle détermine l’ensemble des obligations à respecter. La plupart du temps, un Data Scientist développe un système d’IA et l’entreprise responsable du projet est donc un provider.
Mais certaines situations sont plus nuancées. Prenons le cas d’une ESN qui développe un système d’IA pour le compte d’un client. Le système d’IA étant utilisé ou commercialisé sous la marque du client, c’est ce dernier qui est provider. Le rôle joué par l’ESN peut donc porter à confusion, mais concrètement :
- Tant que le projet est en cours de développement, l’ESN agit comme provider et doit se conformer aux exigences associées.
- Une fois le projet livré, le client devient le provider officiel, responsable des obligations liées à l’industrialisation, à la maintenance ou aux mises à jour et garant des obligations des phases précédentes.
Bien sûr, ce cas est un cas général et il faudra s’assurer de clairement identifier ce transfert de responsabilité, car il a un impact direct sur la manière dont on structure la documentation, les livrables, et les processus de conformité.
3. Mise en place d’un Risk Management System – RMS

L’une des principales obligations des systèmes d’IA à risque élevé est la mise en place d’un système de gestion des risques. En effet, comme nous savons que notre système d’IA représente un fort risque, il faut tout mettre en œuvre pour identifier, évaluer et mitiger ce risque afin qu’il soit maîtrisé. Les risques concernés sont toujours ceux liés à la santé, à la sécurité ou aux droits fondamentaux.
À ce jour, l’AI Act ne fournit pas de framework précis sur la manière dont ce RMS doit être mis en œuvre, mais l’article 9 du texte de loi liste un ensemble de guidelines à suivre. Les différentes instances de gouvernance de la loi viendront préciser ces guidelines officielles avant l’entrée en application complète du texte en août 2027.
Dès la phase de cadrage, nous pouvons réaliser une première itération du RMS en nous concentrant sur les points suivants :
- Identifier les risques liés à l’utilisation normale du système, mais aussi ceux liés à des usages détournés ou incorrects. Par exemple, pour un système dont l’output doit être évalué par un humain avant d’être utilisé, il faut penser à évaluer le risque qui survient si cette supervision humaine n’est plus assurée. Toutes les possibilités doivent être envisagées et il faut donc se poser les questions suivantes : Quelles sont les conditions normales d’utilisation du système et quelles sont les possibles utilisations incorrectes que l’on peut raisonnablement envisager ? Pour chacune d’elles, quels risques peuvent survenir (santé, sécurité et droits fondamentaux des citoyens) ? Pour chaque risque identifié, quelle est la probabilité qu’il survienne et quelle est la gravité de la survenue de ce risque ? Existe-t-il des indicateurs permettant de surveiller ou d’anticiper ces risques ?
- Commencer à réfléchir aux mesures de mitigation : à quel niveau (données, modèle, interface, supervision humaine…) et avec quelles solutions ? Parfois, il faudra attendre la phase de développement pour avoir une meilleure vision de l’aspect technique du système et pour pouvoir y intégrer les meilleurs moyens de mitigation.
Il est essentiel de concevoir le RMS comme un processus vivant et continu, mis à jour à chaque étape du développement et du cycle de vie du système. Nous reviendrons donc sur ce point dans les phases suivantes du workflow Data Science.
II. Ingestion et preprocessing des données

Maintenant que notre projet est bien cadré et que l’on sait où l’on va, nous pouvons passer à l’étape suivante : la sélection, l’ingestion, le prétraitement et l’analyse des données qui serviront à alimenter notre système d’IA. Cette phase est critique car de la qualité des données dépendra directement la performance et la robustesse du modèle entraîné et donc la qualité de notre système d’IA dans son entièreté.
1. Gouvernance des données et rigueur dans la sélection
Avant toute chose, les données doivent naturellement respecter les exigences du RGPD et s’inscrire dans une gouvernance maîtrisée : traçabilité, documentation, accessibilité, droits d’usage.
Dans les grandes structures où plusieurs versions d’un même jeu de données peuvent coexister et où l’on fait face à de très grandes quantités de data, il n’est pas rare de retrouver :
- Des variables similaires représentant des réalités différentes,
- Des granularités hétérogènes,
- Ou des logiques métiers divergentes.
Il est donc essentiel d’opérer un travail de sélection rigoureux avant ingestion, en collaboration étroite avec les experts métier et les responsables des différents périmètres data.
2. Qualité des données : exigences de l’AI Act
L’AI Act porte une attention particulière à la qualité des données utilisées pour l’entraînement des systèmes à haut risque. Plusieurs axes clés doivent être traités à cette étape :
• Biais
Il faudra s’assurer que les biais dans nos data peuvent être monitorés afin de pouvoir les détecter. On veillera à :
- Identifierles biais potentiels dans chaque variable (ex : biais liés au genre, à l’âge, à la localisation…).
- Se demander : s’agit-il d’un biais représentatif de la réalité (ex : disparité naturelle liée au métier) ou d’un biais induit et indésirable (ex : discrimination historique) ?
- Monitorerces biais dans le temps et prévoir des indicateurs pour les suivre.
- Appliquer des stratégies de mitigation adaptées : techniques de rééchantillonnage, de repondération, ou de débiaisement algorithmique. On choisira la méthode la mieux adaptée à notre cas d’usage.
• Représentativité
Il faudra s’assurer que les data utilisées sont bien représentatives de la réalité métier et que les méthodes de mesures et d’échantillonnage n’aient pas biaisé ces données. Pour cela, il faudra donc s’intéresser à la manière dont les données ont été récoltées.
• Complétude
L’absence de données peut fausser l’analyse. On identifiera les champs manquants, et évaluera l’impact de ces absences. On pourra alors choisir la meilleure stratégie de traitement (imputation, exclusion, collecte complémentaire…).
• Précision et erreurs
Il faudra là aussi, autant que possible, disposer d’un dataset sans erreurs. La compréhension du processus de récolte des données nous permettra d’estimer le taux d’erreur du dataset et des mesures possibles pour les détecter et les éliminer.
• Drift
Parfois, la réalité peut évoluer et les distributions des données qui la reflètent vont donc, elles aussi, évoluer au cours du temps. Il est important de suivre ces changements de distribution car le modèle entraîné sur ces données peut ne plus être le meilleur pour identifier les tendances et relations dans les données. On détectera tout drift de data (concept drift ou data drift) et on anticipera le besoin de réentraînement du modèle pour rester aligné avec l’environnement actuel.
• Versioning
Les datasets pouvant être modifiés, il est indispensable d’avoir un système de versionning de données afin de savoir exactement quelles data ont été utilisées pour quelle analyse et d’être en capacité de reproduire les analyses menées.
3. Adapter ses pratiques aux cas d’usage
Il n’existe pas de méthode unique pour garantir la qualité des données : chaque projet, chaque domaine, chaque dataset demande une approche spécifique. On devra donc mettre en place une stratégie sur-mesure, alignée avec les exigences de l’AI Act tout en restant cohérente avec les contraintes métier et techniques.
Et surtout : tout doit être documenté. Chaque choix méthodologique ou technique concernant les données doit être justifié, traçable et mis à disposition pour l’auditabilité et la conformité.
III. Expérimentation et entraînement de modèle
Une fois la qualité des données validée, nous pouvons passer à l’étape centrale du développement : la conception et l’entraînement du modèle, cœur de la majorité des systèmes d’IA.
Les configurations possibles pour un système d’IA sont quasi infinies, de l’enchaînement de modèles aux pipelines conditionnelles mêlant règles métier et modèles de ML, en passant par les systèmes utilisant des LLM fine-tuné ou non, etc.
Pour simplifier l’analyse, nous nous plaçons ici dans un cas général : un modèle unique, entraîné à 100 % sur nos propres données, à l’aide d’une librairie classique (comme scikit-learn, XGBoost, etc.).
Pour les architectures plus complexes, il conviendra d’adapter les principes présentés ici aux spécificités de votre système.
Dans ce cadre, une bonne analyse exploratoire des données permet d’orienter le choix du modèle. Différents modèles peuvent être testés avec une optimisation des hyperparamètres, et le ou les modèles les plus performants sur le dataset de test sont retenus.
Ce modèle sera intégré dans une pipeline complète, avec :
- Un prétraitement des entrées,
- Un post-traitement des sorties,
- Et éventuellement, d’autres logiques métiers.
1. Risk Management System (RMS)
À ce stade, les mesures de mitigation des risques identifiés lors du cadrage doivent être intégrées dans le système. Il est aussi possible que de nouveaux risques émergent au moment de la conception ou de l’entraînement du modèle. On appliquera alors la même procédure d’identification, d’analyse et de mitigation du risque, sans oublier de les documenter.
On devra expérimenter plusieurs méthodes de mitigation et évaluer leur efficacité en conditions réalistes : tests sur jeux de données simulant des cas d’usage typiques ou extrêmes. On pourra alors sélectionner la méthode la plus pertinente en fonction de son impact réel. Cette démarche fait partie intégrante du RMS, qui doit être vivant, évolutif et documenté à chaque itération.
2. Transparence & Supervision Humaine
L’exigence de transparence est l’un des piliers de l’AI Act.
Cela implique que le système doit permettre une bonne interprétation des résultats : l’utilisateur (ou l’auditeur) doit pouvoir comprendre pourquoi une prédiction a été faite. Le système doit aussi permettre unesupervision humaine effective : un humain doit pouvoir surveiller le comportement du système et, si besoin, annuler ou corriger ses décisions.
Le règlement laisse liberté d’implémentation technique sur ces points. À chaque équipe d’adapter les solutions en fonction de son cas d’usage.
Quelques pistes :
- Pour l’explicabilité : on pourra utiliser des librairies comme
SHAP,LIME, les visualisations de feature importance, le scoring de confiance… - Pour la supervision : on pourra mettre en place un workflow de validation humaine, un « bouton d’arrêt », ou des seuils déclenchant des alertes…
Tous ces choix d’implémentation devront être justifiés, tracés et documentés pour garantir la conformité.
3. Cybersécurité
Enfin, l’AI Act rappelle que les best practices en matière de cybersécurité doivent bien évidemment être appliquées à tous les systèmes à haut risque.
IV. Industrialisation du système
Une fois le système conçu et le modèle entraîné, on peut enfin passer à la phase de mise en production de la solution. Peu importe les choix techniques de déploiement (cloud, edge, API, application embarquée, etc.), tout système d’IA à haut risque est soumis à un certain nombre d’obligations préalables avant sa mise en service.
1. Supervision humaine
Il est impératif de s’assurer que la solution de supervision humaine envisagée est compatible avec le mode de déploiement et puisse être maintenue au cours du cycle de vie du système.
Quelques questions à adresser :
- Les référents responsables de la supervision ont-ils été désignés ?
- Existe-t-il un processus clair de désignation ou de remplacement en cas d’absence (vacances, changement de poste, etc.) ?
- Le mécanisme de supervision est-il maintenu tout au long du cycle de vie du système, y compris en phase de scaling ou de réentraînement ?
Tout cela doit être défini et validé en amont du lancement pour garantir une supervision continue et efficace.
2. Notice d’utilisation
Une notice d’utilisation claire et accessible doit être mise à disposition des utilisateurs finaux ou des potentiels deployer.
Elle doit contenir :
- Les instructions d’utilisation du système (ce qu’il fait et ce qu’il ne doit pas faire),
- Une description synthétique de son fonctionnement dans un souci de transparence,
- Les modalités d’interprétation des sorties du système,
- Les risques identifiés ainsi que les mesures de mitigation mises en place.
Cette notice est essentielle pour garantir une utilisation responsable du système d’IA.
3. Documentation technique et réglementaire
Une documentation complète retraçant l’ensemble des analyses, des décisions de conception et des choix techniques doit être élaborée.
Ses deux objectifs :
- Démontrer la conformité au regard de l’AI Act, en prouvant que toutes les mesures raisonnables ont été prises pour prévenir et atténuer les risques identifiés.
- Assurer la maintenabilité du système.
Cette documentation doit être complétée avant le déploiement de la solution et accessible aux différents acteurs concernés.
4. Enregistrement du système
Selon l’article 49 de l’AI Act, tout système à haut risque ainsi que l’entité provider doivent être enregistrés dans une base de données européenne dédiée avant leur mise en service.
Les modalités précises de cette base sont décrites à l’article 71. À ce jour, la plateforme n’est pas encore opérationnelle, mais sa création est prévue par l’AI Office dans les mois précédant l’entrée en vigueur des obligations des systèmes à haut risque.
Il est donc conseillé de préparer l’ensemble des informations nécessaires à cet enregistrement dès maintenant.
5. Marquage CE

Avant toute mise en service ou commercialisation, le système doit également obtenir un marquage CE, preuve de sa conformité réglementaire.
Cela implique :
- La réalisation d’une évaluation de conformité complète,
- La rédaction d’une déclaration de conformité à l’AI Act, à conserver à disposition des autorités nationales,
- L’obtention du marquage CE auprès d’un organisme notifiéempowered.
To date, the official award process and the notified bodies responsible for issuing the CE mark have not yet been designated. Once they are, we can refer to the list of notified bodies for legislation (2024/1689).
Once all these obligations have been met, the system can then be put into production and made available to end users.
V. Post-deployment monitoring
Deploying the system is not the end of the work. On the contrary, The AI Act requires rigorous monitoring during the operational phase, to ensure that the system remains compliant, reliable, and secure throughout its lifecycle.
Drift model
It is important to detect changes in the distribution of input or output data over time. Indeed, this could indicate a change in the real environment or a gradual deterioration in the performance of the model. In the event of proven drift, a retraining, an update of the model or an adaptation of the design may be considered.
Retention of operating logs
Another essential requirement: maintenance of operating logs. These logs, recorded automatically, should make it possible to analyze the behavior of the system, in particular in the event of an audit or the occurrence of a risk. They play a central role in the traceability and analysis of incidents.
Risk Management System
Our RMS now comes in after the deployment of our system. It's about staying attentive to theemergence of new risks not identified during initial development. The analysis of field feedback and operating logs makes it possible to detect these new risks. Any new threat must be analyzed, evaluated and documented, and new mitigation measures must be integrated into a corrective system update.
Incident Monitoring and Reporting
Finally, despite all the efforts put in place to eliminate or minimize the risk, incidents can still happen. We are talking here about incidents related to risks to the health, safety and fundamental rights of citizens and not purely technical incidents (although a system interruption may in some cases represent a nuisance for users). For each incident, it will be necessary to:
- ensure that a proven or probable causal link exists between the event and the AI system,
- report it to the competent authorities within 15 days of its discovery,
- conduct an internal investigation to understand the causes of the incident and put in place the necessary corrective measures.
Further details on this procedure are expected from the AI Act governance bodies.
In summary, post-deployment monitoring is not a simple formality: it is a proactive, continuous and documented approach, essential to guarantee the reliability, transparency and compliance of high-risk AI systems over time.
VI. Quality Management System (QMS)
As we have just seen, complying with the AI Act involves numerous obligations that may, at first glance, seem complex to orchestrate as a whole.
To ensure that each regulatory requirement is properly taken into account throughout the life cycle of an AI system, the AI Act requires the establishment of a Quality Management System (QMS). The purpose of this methodological framework is to structure internal practices by centralizing the procedures, policies and instructions necessary to comply with the requirements of the regulation.
In particular, the QMS must contain:
- A global compliance strategy for all AI systems developed or used by the company.
- The systematic integration of all the steps described in this article, from the scoping phase to post-deployment monitoring.
- A reminder of the standards and best practices to be respected in development.
- Protocols for testing and validating risk reduction methods.
- The inclusion of the Risk Management System, as well as associated risk monitoring and review processes.
- Incident reporting procedures, in collaboration with the competent authorities.
- Coordination with monitoring and alert tools, in order to monitor operation in real time.
- Documentation management: user manuals, technical decision histories, operating logs.
- A process for managing system updates, ensuring that any changes automatically trigger the necessary tests, verifications, mitigation measures and monitoring actions.
- Management and monitoring of communication with the various actors in connection with the AI system as well as the competent national authorities and notified bodies.
- A clear definition of governance around systems, specifying the roles, responsibilities and processes for designating referents.
Here too, the regulation does not set a single format for this quality system, leaving companies with freedom of implementation in proportion to their size and resources (as specified inSection 17). It is therefore up to each structure to define a solution adapted to its context.
In conclusion
The AI Act is profoundly transforming Data Science practices, especially for high-risk systems. More than a constraint, it offers an opportunity to reinforce the rigor and transparency of models.
Adapting workflows means professionalizing AI, streamlining collaboration between teams and preparing for a future where compliance will be a lever of trust and a competitive advantage.
The road is not easy: it will be necessary to rethink certain stages of the model life cycle, implement new governance tools and above all create a fluid dialogue between technical, legal and business teams. But organizations that successfully make this transition will have a clear strategic advantage: that of being able to deploy responsible and compliant AI systems in an increasingly demanding regulatory landscape.
In a future article, we will explore how to set up an AI governance system within an organization in order to ensure the quality and compliance of our systems.