En este artículo vamos a ver cómo adaptar nuestro flujo de trabajo de ciencia de datos para cumplir con la Ley de IA
Seguiremos cada etapa del ciclo de desarrollo de un sistema de IA, desde la fase de análisis inicial hasta la industrialización y el monitoreo, incluida la fase de preprocesamiento de datos y entrenamiento de modelos.
Para ello, nos pondremos en la piel de un Proveedor trabajando en un sistema de IA clasificado en alto riesgo. De hecho, como científicos de datos, a menudo asumimos esta función cuando diseñamos, entrenamos o implementamos sistemas de inteligencia artificial para uso interno o con fines de marketing (consulte la parte III del artículo anterior).
Es importante tener en cuenta que las obligaciones reglamentarias y, por lo tanto, los métodos de trabajo y las mejores prácticas resultantes varían según la categoría de riesgo del sistema. Si el sistema que está desarrollando presenta un riesgo bajo o moderado, el nivel de exigencia será diferente.
Por último, para mantener una lectura clara, nos centraremos aquí en el caso general. Sin embargo, hay muchas situaciones específicas, por ejemplo, el uso de un modelo previamente entrenado que ajustamos con precisión. En tal caso, será necesario verificar la conformidad del modelo inicial previamente entrenado y, a continuación, aplicar todos los requisitos del proveedor al nuevo modelo perfeccionado.

I. Marco del proyecto
Como ocurre con cualquier proyecto de IA, el primer paso es alcance. Se trata de definir claramente las necesidades y limitaciones empresariales, las restricciones técnicas, presupuestarias y de ciberseguridad, así como los métodos de uso del sistema por parte de los usuarios finales. Con la entrada en vigor de la Ley de Inteligencia Artificial, esta fase adquiere una dimensión adicional: evaluación de riesgos regulatorios Y el determinar nuestro papel en la cadena de cumplimiento.
1. Identificar el nivel de riesgo del sistema
La Ley de IA clasifica los sistemas de IA según su nivel de riesgo. Como este nivel depende del caso de uso y no de la tecnología utilizada, puede (y debe) definirse ya en la fase de análisis. Además, esta identificación es crucial para conocer las obligaciones reglamentarias que deben respetarse en el futuro desarrollo del sistema.
2. Determinar nuestro papel con respecto a la Ley de Inteligencia Artificial
Como recordatorio, la Ley de IA define varias funciones reguladoras (proveedor, despliegue, importación, distribuidor). Es esencial identificar el rol que cada uno desempeña, porque este rol determina todas las obligaciones que deben respetarse. La mayoría de las veces, un científico de datos desarrolla un sistema de inteligencia artificial y, por lo tanto, la empresa responsable del proyecto es Proveedor.
Sin embargo, algunas situaciones son más matizadas. Tomemos el caso de una empresa de TI que desarrolla un sistema de inteligencia artificial para un cliente. Como el sistema de IA se utiliza o comercializa con la marca del cliente, el proveedor es el cliente. Por lo tanto, el papel desempeñado por la ESN puede resultar confuso, pero en términos concretos:
- Mientras el proyecto esté en desarrollo, la ESN actúa como proveedor y debe cumplir con los requisitos asociados.
- Una vez entregado el proyecto, el cliente se convierte en el proveedor oficial, responsable de las obligaciones relacionadas con la industrialización, el mantenimiento o las actualizaciones y garantizando las obligaciones de las fases anteriores.
Por supuesto, este es un caso general y debe asegurarse de identificar claramente esta transferencia de responsabilidad, ya que tiene un impacto directo en la forma en que se estructuran la documentación, los entregables y los procesos de cumplimiento.
3. Configuración de un sistema de gestión de riesgos — RMS

Una de las principales obligaciones de los sistemas de IA de alto riesgo es el establecimiento de un sistema de gestión de riesgos. De hecho, como sabemos que nuestro sistema de IA representa un alto riesgo, debemos hacer todo lo posible para identificar, evaluar y mitigar este riesgo para poder controlarlo. Los riesgos en cuestión son siempre los relacionados con salud, seguridad O en derechos fundamentales.
Hasta la fecha, la Ley de IA no proporciona un marco específico sobre cómo debe implementarse este RMS, pero elartículo 9 de la ley enumera un conjunto de pautas a seguir. Los distintos órganos de gobierno legal especificarán estas directrices oficiales antes de que el texto entre en plena aplicación en agosto de 2027.
Desde la fase de análisis, podemos llevar a cabo una primera iteración del RMS centrándonos en los siguientes puntos:
- Identifique los riesgos relacionados con el uso normal del sistema, pero también con los relacionados con un uso indebido o incorrecto. Por ejemplo, en el caso de un sistema cuyo rendimiento debe ser evaluado por una persona antes de usarlo, hay que pensar en evaluar el riesgo que se corre si se deja de proporcionar esta supervisión humana. Deberían tenerse en cuenta todas las posibilidades y, por lo tanto, plantearse las siguientes preguntas: ¿Cuáles son las condiciones normales de uso del sistema y cuáles son los posibles usos incorrectos que cabría considerar razonablemente? Para cada uno de ellos, ¿qué riesgos pueden presentarse (salud, seguridad y derechos fundamentales de los ciudadanos)? Para cada riesgo identificado, ¿cuál es la probabilidad de que se produzca y cuál es la gravedad de la aparición de este riesgo? ¿Existen indicadores para monitorear o anticipar estos riesgos?
- Empieza a pensar en medidas de mitigación : ¿a qué nivel (datos, modelo, interfaz, supervisión humana...) y con qué soluciones? A veces, tendrá que esperar a la fase de desarrollo para tener una mejor visión del aspecto técnico del sistema y poder integrar los mejores métodos de mitigación.
Es fundamental diseñar el El RMS como un proceso vivo y continuo, actualizado en cada etapa del desarrollo y del ciclo de vida del sistema. Por lo tanto, volveremos a este punto en las siguientes fases del flujo de trabajo de la ciencia de datos.
II. Ingestión y preprocesamiento de datos

Ahora que nuestro proyecto está bien definido y que sabemos hacia dónde vamos, podemos pasar al siguiente paso: selección, ingestión, preprocesamiento y análisis de datos que se utilizará para alimentar nuestro sistema de inteligencia artificial. Esta fase es fundamental porque la calidad de los datos dependerá directamente del rendimiento y la solidez del modelo entrenado y, por lo tanto, de la calidad de todo nuestro sistema de IA.
1. Gobernanza de datos y rigor en la selección
Por encima de todo, los datos deben cumplir naturalmente con los requisitos del RGPD y formar parte de una gobernanza controlada: trazabilidad, documentación, accesibilidad, derechos de uso.
En estructuras grandes en las que pueden coexistir varias versiones de un mismo conjunto de datos y en las que se trata de cantidades muy grandes de datos, no es raro encontrar:
- Variables similares que representan realidades diferentes,
- Granularidades heterogéneas,
- O lógicas empresariales divergentes.
Por lo tanto, es esencial llevar a cabo un riguroso trabajo de selección antes de la ingestión, en estrecha colaboración con los expertos empresariales y los administradores de los distintos perímetros de datos.
2. Calidad de los datos: requisitos de la Ley de IA
La Ley de IA presta especial atención a la calidad de datos utilizado para entrenar sistemas de alto riesgo. En esta fase es necesario abordar varias áreas clave:
• Prejuicio
Tendremos que asegurarnos de que los sesgos de nuestros datos puedan monitorearse para poder detectarlos. Se procurará lo siguiente:
- Identificarposibles sesgos en cada variable (por ejemplo, sesgos relacionados con el género, la edad, la ubicación, etc.).
- Pregúntese: ¿es un sesgo representativo de la realidad (por ejemplo, una disparidad natural vinculada a la profesión) o un sesgo inducido e indeseable (por ejemplo, una discriminación histórica)?
- Supervisarestos sesgos a lo largo del tiempo y proporcionan indicadores para monitorearlos.
- Aplica estrategias de mitigación adaptado: técnicas de remuestreo, reponderación o sesgo algorítmico. Elegiremos el método que mejor se adapte a nuestro caso de uso.
• Representatividad
Será necesario garantizar que los datos utilizados sean representativos de la realidad empresarial y que los métodos de medición y muestreo no hayan sesgado estos datos. Para ello, será necesario, por tanto, analizar cómo se recopilaron los datos.
• Integridad
La ausencia de datos puede sesgar el análisis. Se identificarán los campos que faltan y se evaluará el impacto de estas ausencias. Luego podemos elegir la mejor estrategia de tratamiento (imputación, exclusión, recolección adicional, etc.).
• Precisión y errores
También en este caso, en la medida de lo posible, será necesario tener un conjunto de datos libre de errores. Comprender el proceso de recopilación de datos nos permitirá estimar la tasa de error del conjunto de datos y las posibles medidas para detectarlos y eliminarlos.
• Deriva
A veces, la realidad puede cambiar y, por lo tanto, las distribuciones de los datos que la reflejan también cambiarán con el tiempo. Es importante hacer un seguimiento de estos cambios en la distribución porque es posible que el modelo basado en estos datos ya no sea el mejor para identificar las tendencias y las relaciones en los datos. Detectaremos cualquier desviación de datos (desviación de conceptos o de datos) y anticiparemos la necesidad de volver a capacitar el modelo para que se mantenga alineado con el entorno actual.
• Control de versiones
Dado que los conjuntos de datos se pueden modificar, es esencial contar con un sistema de control de versiones de datos para saber exactamente qué datos se utilizaron para cada análisis y poder reproducir los análisis realizados.
3. Adaptación de las prácticas a los casos de uso
No existe un método único para garantizar la calidad de los datos: cada proyecto, cada dominio, cada conjunto de datos requiere un enfoque específico. Por lo tanto, tendremos que crear un estrategia a medida, alineado con los requisitos de la Ley de IA sin dejar de ser coherente con las restricciones comerciales y técnicas.
Y sobre todo: todo debe estar documentado. Cada elección metodológica o técnica relativa a los datos debe estar justificada, ser rastreable y estar disponible para su auditabilidad y cumplimiento.
III. Experimentación y entrenamiento de modelos
Una vez que se haya validado la calidad de los datos, podemos pasar a la etapa central de desarrollo: el diseño y la formación del modelo, el núcleo de la mayoría de los sistemas de IA.
Las configuraciones posibles para un sistema de IA son casi infinitas, desde cadenas de modelos hasta canalizaciones condicionales que combinan reglas comerciales y modelos de aprendizaje automático, incluidos los sistemas que utilizan LLM ajustados o no ajustados, etc.
Para simplificar el análisis, nos planteamos un caso general: un modelo único, entrenado al 100% con nuestros propios datos, utilizando una biblioteca tradicional (como Scikit-Learn, XG Boost, etc.).
Para arquitecturas más complejas, los principios que se presentan aquí deben adaptarse a las especificidades de su sistema.
En este contexto, un buen análisis exploratorio de los datos permite orientar la elección del modelo. Se pueden probar diferentes modelos con la optimización de hiperparámetros y se seleccionan el modelo o los modelos que funcionan mejor en el conjunto de datos de prueba.
Este modelo se integrará en una cartera completa, con:
- Tratamiento previo de los insumos,
- Procesamiento posterior de los resultados,
- Y posiblemente, otras lógicas empresariales.
1. Sistema de gestión de riesgos (RMS)
En este punto, el medidas de mitigación de riesgos identificados durante el encuadre deben estar integrados en el sistema. También es posible que están surgiendo nuevos riesgos en el momento en que se diseñó o entrenó el modelo. Luego se aplicará el mismo procedimiento para identificar, analizar y mitigar el riesgo, sin olvidar documentarlos.
Tendremos que experimentar con varios métodos de mitigación y evaluar sus eficiencia en condiciones realistas : pruebas en conjuntos de datos que simulan casos de uso típicos o extremos. A continuación, podemos seleccionar el método más relevante en función de su impacto real. Este enfoque es una parte integral del RMS, que debe ser viviendo, evolucionando y documentándose en cada iteración.
2. Transparencia y supervisión humana
El requisito de transparencia es uno de los pilares de la Ley de IA.
Esto implica que el sistema debe permitir una buena interpretación de los resultados : el usuario (o el oyente) debe poder entender por lo tanto se ha hecho una predicción. El sistema también debe permitirsupervisión humana efectivo: un ser humano debe poder monitorear el comportamiento del sistema y, si es necesario, cancelar o corregir sus decisiones.
El reglamento deja libertad de implementación técnica en estos puntos. Depende de cada equipo adaptar las soluciones de acuerdo con su caso de uso.
Algunos consejos:
- Para facilitar la explicación: podemos usar bibliotecas como
FORMA,LIMA, visualizaciones de la importancia de las funciones, puntuación de confianza... - Para la supervisión: podemos configurar un flujo de trabajo de validación humana, un «botón de parada» o umbrales que activen alertas...
Todas estas opciones de implementación deberán justificarse, rastrearse y documentarse para garantizar el cumplimiento.
3. Ciberseguridad
Por último, la Ley de IA nos recuerda que, por supuesto, las mejores prácticas de ciberseguridad deben aplicarse a todos los sistemas de alto riesgo.
IV. Industrialización del sistema
Una vez diseñado el sistema y entrenado el modelo, por fin podemos pasar a la fase de poner la solución en producción. Independientemente de las opciones técnicas de implementación (nube, perimetral, API, aplicación integrada, etc.), cualquier sistema de IA de alto riesgo está sujeto a una serie de obligaciones previas antes de su puesta en servicio.
1. Supervisión humana
Es imprescindible garantizar que la solución de supervisión humana que se está considerando sea compatible con el modo de implementación y pueda mantenerse durante el ciclo de vida del sistema.
Algunas preguntas para hacer:
- ¿Se han nombrado los árbitros responsables de la supervisión?
- ¿Existe un proceso claro para designar o reemplazar a alguien en caso de ausencia (vacaciones, cambio de trabajo, etc.)?
- ¿Se mantiene el mecanismo de supervisión durante todo el ciclo de vida del sistema, incluso durante el escalado o el readiestramiento?
Todo esto debe definirse y validarse antes del lanzamiento para garantizar una supervisión continua y eficaz.
2. Instrucciones de uso
Uno instrucciones de uso debe ponerse a disposición de los usuarios finales o posibles implementadores, de forma clara y accesible.
Debe contener:
- Instrucciones de uso del sistema (qué hace y qué no debe hacer),
- Una descripción resumida de su funcionamiento en aras de la transparencia,
- Los métodos de interpretación de las salidas del sistema,
- Los riesgos identificados, así como las medidas de mitigación implementadas.
Este aviso es esencial para garantizar un uso responsable del sistema de IA.
3. Documentación técnica y reglamentaria
Uno documentación completa se deben desarrollar resumiendo todos los análisis, decisiones de diseño y elecciones técnicas.
Sus dos objetivos:
- Demuestre el cumplimiento en virtud de la Ley de Amnistía Internacional, demostrando que se han tomado todas las medidas razonables para prevenir y mitigar los riesgos identificados.
- Garantizar la mantenibilidad del sistema.
Esta documentación debe completarse antes de implementar la solución y estar accesible para los distintos actores involucrados.
4. Registro del sistema
Según elartículo 49 de la Ley de Amnistía Internacional, cualquier sistema de alto riesgo, así como la entidad proveedora, deben estar registrados en un base de datos europea dedicada antes de que se pongan en servicio.
Las modalidades precisas de esta base de datos se describen enArtículo 71. Hasta la fecha, la plataforma aún no está operativa, pero la Oficina de Inteligencia Artificial planea su creación en los meses anteriores a la entrada en vigor de las obligaciones de los sistemas de alto riesgo.
Por lo tanto, es recomendable preparar ahora toda la información necesaria para este registro.
5. Marcado CE

Antes de la puesta en marcha o la comercialización, el sistema también debe obtener un Marcado CE, prueba de su cumplimiento normativo.
Esto implica:
- La realización de un evaluación de conformidad completo,
- La escritura de un Declaración de cumplimiento de la Ley AI, que se mantendrá a disposición de las autoridades nacionales,
- Obtención de la marca CE de un organismo notificadoempoderado.
Hasta la fecha, el proceso oficial de adjudicación y los organismos notificados responsables de emitir la marca CE aún no han sido designados. Una vez que lo estén, podemos consultar la lista de organismos notificados para legislación (2024/1689).
Una vez que se hayan cumplido todas estas obligaciones, el sistema puede ponerse en producción y ponerse a disposición de los usuarios finales.
V. Supervisión posterior al despliegue
La implementación del sistema no es el final del trabajo. Por el contrario, La Ley de Inteligencia Artificial exige una supervisión rigurosa durante la fase operativa, para garantizar que el sistema siga siendo compatible, confiable y seguro durante todo su ciclo de vida.
Modelo Drift
Es importante detectar cambios en la distribución de los datos de entrada o salida a lo largo del tiempo. De hecho, esto podría indicar un cambio en el entorno real o un deterioro gradual del rendimiento del modelo. En caso de que se demuestre una desviación, se puede considerar la posibilidad de volver a capacitarse, actualizar el modelo o adaptar el diseño.
Retención de registros operativos
Otro requisito imprescindible: mantenimiento de los registros de operación. Estos registros, registrados automáticamente, deberían permitir analizar el comportamiento del sistema, en particular en caso de una auditoría o de la aparición de un riesgo. Desempeñan un papel central en la trazabilidad y el análisis de los incidentes.
Sistema de gestión de riesgos
Nuestro RMS ahora llega después de la implementación de nuestro sistema. Se trata de permanecer atentos a laaparición de nuevos riesgos no identificado durante el desarrollo inicial. El análisis de los comentarios de campo y los registros de operación permite detectar estos nuevos riesgos. Cualquier nueva amenaza debe analizarse, evaluarse y documentarse, y las nuevas medidas de mitigación deben integrarse en una actualización correctiva del sistema.
Monitorización e informes de incidentes
Por último, a pesar de todos los esfuerzos realizados para eliminar o minimizar el riesgo, los incidentes aún pueden ocurrir. Estamos hablando de incidentes relacionados con riesgos para la salud, la seguridad y los derechos fundamentales de los ciudadanos y no de incidentes puramente técnicos (aunque una interrupción del sistema en algunos casos puede representar una molestia para los usuarios). Para cada incidente, será necesario:
- garantizar que existe una relación causal probada o probable entre el suceso y el sistema de IA,
- denunciarlo a las autoridades competentes en un plazo de 15 días a partir de su descubrimiento,
- llevar a cabo una investigación interna para comprender las causas del incidente y establecer las medidas correctivas necesarias.
Se espera que los órganos de gobierno de la Ley de Inteligencia Artificial proporcionen más detalles sobre este procedimiento.
En resumen, el monitoreo posterior al despliegue no es una simple formalidad: es un enfoque proactivo, continuo y documentado, esencial para garantizar la confiabilidad, la transparencia y el cumplimiento de los sistemas de IA de alto riesgo a lo largo del tiempo.
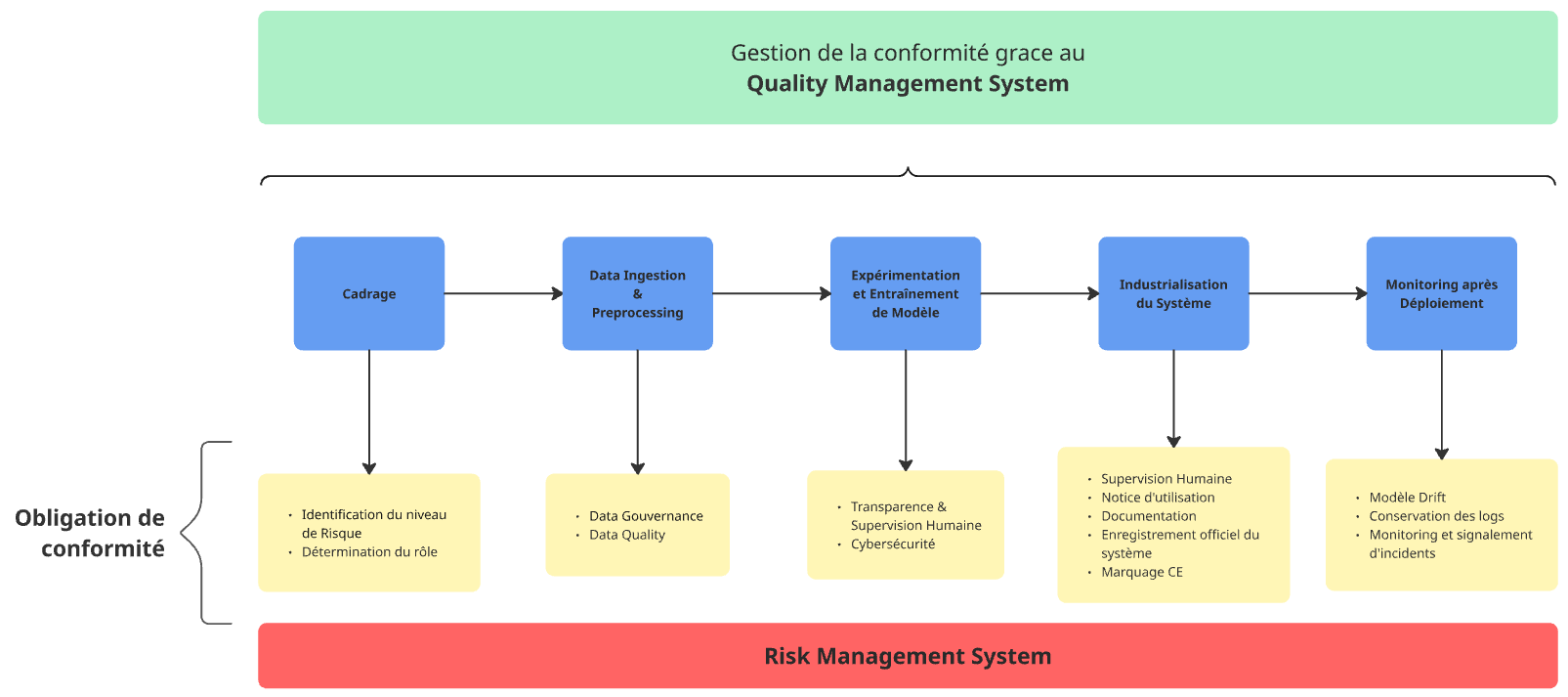
VI. Sistema de gestión de calidad (QMS)
Como acabamos de ver, el cumplimiento de la Ley de IA implica numerosas obligaciones que, a primera vista, pueden parecer complejas de orquestar en su conjunto.
Para garantizar que cada requisito reglamentario se tenga debidamente en cuenta a lo largo del ciclo de vida de un sistema de IA, la Ley de IA exige el establecimiento de un Sistema de gestión de calidad (QMS). El propósito de este marco metodológico es estructurar las prácticas internas centralizando los procedimientos, políticas e instrucciones necesarios para cumplir con los requisitos del reglamento.
En particular, el QMS debe contener:
- Una estrategia de cumplimiento global para todos los sistemas de IA desarrollados o utilizados por la empresa.
- La integración sistemática de todos los pasos descritos en este artículo, desde la fase de análisis hasta la supervisión posterior al despliegue.
- Un recordatorio de los estándares y las mejores prácticas que deben respetarse en el desarrollo.
- Protocolos para probar y validar los métodos de reducción de riesgos.
- La inclusión del Sistema de Gestión de Riesgos, así como los procesos de monitoreo y revisión de riesgos asociados.
- Procedimientos de notificación de incidentes, en colaboración con las autoridades competentes.
- Coordinación con herramientas de monitoreo y alerta, para monitorear la operación en tiempo real.
- Gestión de la documentación: manuales de usuario, historiales de decisiones técnicas, registros operativos.
- Un proceso para administrar las actualizaciones del sistema, garantizando que cualquier cambio desencadene automáticamente las pruebas, verificaciones, medidas de mitigación y acciones de monitoreo necesarias.
- Gestión y seguimiento de la comunicación con los distintos actores relacionados con el sistema de IA, así como con las autoridades nacionales competentes y los organismos notificados.
- Una definición clara de la gobernanza en torno a los sistemas, especificando las funciones, las responsabilidades y los procesos para designar los referentes.
También en este caso, el reglamento no establece un formato único para este sistema de calidad, lo que deja a las empresas libertad de implementación en proporción a su tamaño y recursos (tal como se especifica enSección 17). Por lo tanto, corresponde a cada estructura definir una solución adaptada a su contexto.
En conclusión
La Ley de IA está transformando profundamente las prácticas de ciencia de datos, especialmente para los sistemas de alto riesgo. Más que una restricción, ofrece una oportunidad para reforzar el rigor y la transparencia de los modelos.
Adaptar los flujos de trabajo significa profesionalizar la IA, agilizar la colaboración entre los equipos y prepararse para un futuro en el que el cumplimiento sea una palanca de confianza y una ventaja competitiva.
El camino no es fácil: será necesario repensar ciertas etapas del ciclo de vida del modelo, implementar nuevas herramientas de gobierno y, sobre todo, crear un diálogo fluido entre los equipos técnicos, legales y empresariales. Sin embargo, las organizaciones que hagan esta transición con éxito tendrán una clara ventaja estratégica: la de poder implementar sistemas de inteligencia artificial responsables y compatibles en un panorama regulatorio cada vez más exigente.
En un artículo futuro, exploraremos cómo configurar un sistema de gobierno de IA dentro de una organización para garantizar la calidad y el cumplimiento de nuestros sistemas.