Hoy en día, la diversidad es el santo grial de la precisión de los modelos: Deep Forest es un marco prometedor basado en capas de aprendizaje profundo, pero sin neuronas ni retropropagación. Los revolucionarios marcos de los bosques profundos permiten introducir la diversidad como la punta del iceberg. El siguiente artículo presentará el marco y la diversidad, y demostrará cómo aplicar sus diversos modelos de conjuntos a este novedoso marco.
Por Simón PROVOST, ingeniero de datos en LittleBigCode

Si bien los enfoques conjuntos dan excelentes resultados hoy en día, Zhi-Hua Zhou Y Ji Feng Indiquen en su trabajo sobre una metodología novedosa de aprendizaje profundo que, cuando un bosque aleatorio produce resultados decentes en sus datos, aplique un bosque profundo y se sorprenderá gratamente. La propuesta de Zhi-Hua Zhou y Ji Feng de crear un marco revolucionario de aprendizaje profundo denominado Deep Forest (DF) puede considerarse uno de los acontecimientos más importantes del aprendizaje automático de 2017.
El DF emplea una serie de enfoques basados en conjuntos, más comúnmente Random Forests (RF) y Stacking, para generar una estructura similar a la de una red neuronal de múltiples capas, excepto que cada capa está hecha de RF en lugar de neuronas. El DF es particularmente favorable para el entrenamiento porque requiere un número reducido de hiperparámetros, no requiere retropropagación y supera a algunas técnicas conocidas, como las redes neuronales profundas, cuando solo se dispone de datos de entrenamiento a pequeña escala.
La mejora de la diversidad es una técnica que consiste en combinar numerosos alumnos «débiles» o «débiles» o «débiles»/«eficientes» en un solo alumno «fuerte», donde «débil» es relativo. Como resultado, la teoría del apilamiento debería minimizar tanto el sesgo como la variación, y es particularmente eficaz para evitar el sobreajuste y la varianza. Esto se debe a dos motivos:
- Cada alumno del conjunto tendrá una forma algo diferente de asignar las características a los resultados, y la idea es que, al combinarlos, se cubra una mayor parte del área de búsqueda.
- Además, tomando el primer y el segundo modelo de un conjunto, ambos tienen un sesgo bajo pero una varianza alta debido al sobreajuste, teóricamente han sobreajustado regiones separadas del espacio de búsqueda; después de combinarlas, la varianza general se reduciría.
Como consecuencia, el aprendizaje conjunto con un enfoque en la diversidad (es decir, elige a tus alumnos con cuidado) Se traducirá en una reducción de la varianza general. Además, en la práctica, esto se suele añadir al conjunto inyectando aleatoriedad durante el entrenamiento.
Como creo que la diversidad de nuestros modelos es el próximo avance, entre otros, en el aprendizaje automático, he aquí una descripción más general de cómo el DF incluye la gestión de la diversidad y por qué es fundamental en el aprendizaje automático o, más precisamente, en la combinación de enfoques y apilamiento.
El siguiente artículo comienza con una descripción general de cómo funciona el DF, seguido de una breve explicación de por qué la diversidad es importante en el DF y, a continuación, una introducción rápida sobre cómo mejorar la diversidad con el marco del DF (perspectiva práctica).
¿Cómo funciona Deep Forest en general?
Debido a que el artículo original lo establece de manera muy efectiva y sucinta, la siguiente explicación tendrá un alcance amplio; por lo tanto, para el componente matemático, consulte también los artículos originales. Por lo tanto, analizaremos los componentes de clasificación y predicción de la arquitectura de Deep Forest utilizando el siguiente diagrama:
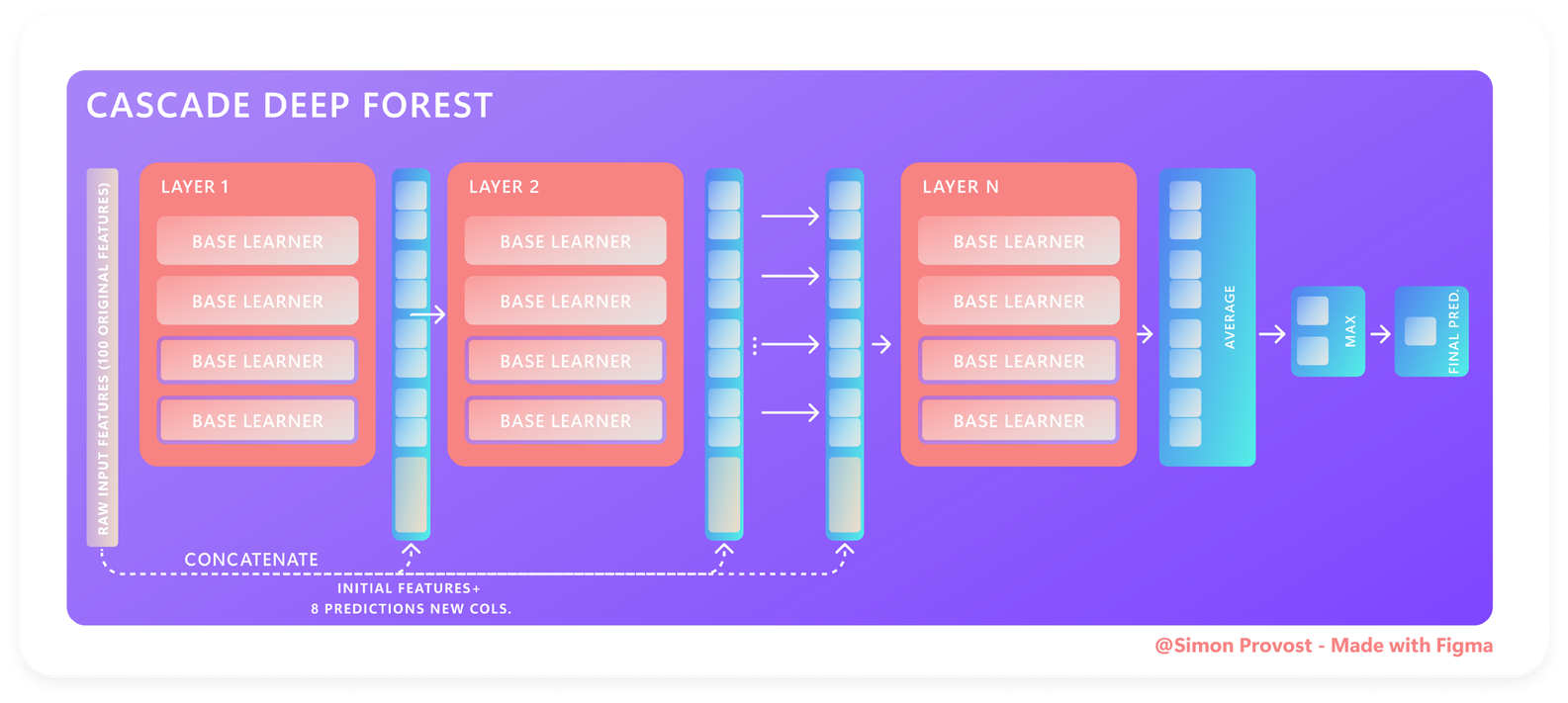
Capa por capa, así es como funciona Deep Forest Architecture:
- La primera capa se suministra con el vector de características sin procesar inicial y, a continuación,
Nse ejecutan los estimadores configurados previamente, cada uno de los cuales produce un vector de predicción (es decir, clasificación de clases binarias: dos salidas, clasificación de clases múltiples:Clase Nsalidas). - Los vectores de predicción se concatenan con la entrada de la segunda capa junto con el vector sin procesar inicial, lo que naturalmente aumenta la dimensionalidad de las características con cada capa subsiguiente, y así sucesivamente.
- En última instancia, se determina un promedio de los resultados de cada capa;
- Y, por último, se genera una función máxima para obtener la predicción final.
Buena nota:Si bien los procesos anteriores están automatizados, el primer paso se puede realizar de forma manual o automática utilizando la combinación de conjuntos predeterminada especificada por los diseñadores del marco. Para hacerlo manualmente, lee el resto de este artículo para aprender a hacerlo.
¿Cómo se aplica la diversidad en Deep Forest?
La diversidad es un tema de estudio muy amplio, y aquí analizaremos cómo debe pensar un ingeniero al seleccionar a sus alumnos básicos (es decir, los algoritmos). A continuación, concluiremos mostrando cómo estas tres técnicas aplican la «diversidad»:
- Los primeros métodos parecen seguir los usos de los bosques aleatorios; por lo tanto, basado en muestras. Esta técnica aplica la diversidad muestra por muestra, lo que implica que cada modelo del conjunto buscará en una parte diferente del espacio general de los datos y, por lo tanto, cubrirá todos los datos de manera más efectiva.
- Métodos basados en hiperparámetros, que tiende a decir que es mejor optimizar el modelo directamente en lugar de combinar algoritmos precisos, para aumentar la mejora de los resultados de la diversidad; por lo tanto, cada modelo tiene una función objetiva basada en una variedad de medidas elegidas, y los profesionales deben modificar el hiperparámetro para lograr la función objetivo, de modo que los resultados generales se diversifiquen desde una perspectiva hiperparamétrica.
- Por último, Métodos basados en la clasificación, que toma una lista de alumnos (diversificados o no), los clasifica según los criterios de diversidad esta vez y selecciona el L Uno como modelo final (Por ejemplo, el método basado en clústeres implica trazar los resultados del modelo en un espacio bidimensional y agruparlos [automáticamente o no] para extraer solo aquellos que se correlacionan con el criterio dado).
Como resultado, según el enfoque utilizado para seleccionar a los alumnos para el conjunto, la diversidad se aplicará de manera diferente, según si la vista se basa en muestras, en hiperparámetros o en algoritmos. Por último, el DF se utilizará en la perspectiva final cuando se calcule el promedio de los alumnos del conjunto para obtener uno, momento en el que la diversidad se aplicará a las conclusiones de los alumnos que haya seleccionado previamente utilizando las breves técnicas descritas anteriormente.
¿Por qué la diversidad en Deep Forest?
Debido al enfoque principal de la teoría del DF en el conjunto y el apilamiento, la diversidad es otro componente clave incluido en el paquete. Sin embargo, ¿por qué es un componente tan importante del marco?
¿Qué es el aprendizaje en conjunto y los subparadigmas de empaquetar, impulsar y apilar?
Del documento de GCForest a Deep Forest actualizado en 2019: Aprendizaje en conjunto es un paradigma de aprendizaje automático en el que una tarea se resuelve mediante la formación y la combinación de varios alumnos (por ejemplo, clasificadores). Por lo tanto, entre los métodos de aprendizaje conjunto tenemos:
- Ensacado que con frecuencia considera a los alumnos débiles homogéneos, los aprende de forma independiente unos de otros en paralelo y, a continuación, los combina mediante un proceso de promediación determinista;
- Impulsando Que con frecuencia considera a los alumnos débiles homogéneos, los aprende secuencialmente de una manera altamente adaptativa (un modelo base depende de los anteriores) y luego los combina mediante una estrategia determinista; y finalmente;
- Apilamiento, por otro lado, con frecuencia considera a los alumnos débiles heterogéneos, los aprende en paralelo y los agrega mediante el entrenamiento de un metamodelo para generar una predicción basada en los resultados de los muchos modelos débiles.
¿Por qué la diversidad tiene que ver con el apilamiento?
Debido a la manera heterogénea en que se produce el apilamiento, la diversidad desempeña un papel fundamental a la hora de permitir esto. Como se mencionó brevemente anteriormente en el artículo, la diversidad permite desarrollar modelos de conjuntos sólidos; esto también se afirma en el artículo original del DF: «para construir un conjunto sólido, los alumnos individuales deben ser precisos y diferentes».
La combinación de alumnos puramente correctos es con frecuencia inferior a la combinación de algunos alumnos acertados con otros comparativamente más débiles, ya que la complementariedad prevalece sobre la precisión pura. Sin embargo, los científicos siguen enfrentándose al mismo enigma: «¿Qué es realmente la diversidad? «Esta pregunta sigue siendo el santo grial del campo.
Por último, dado que la diversidad es un componente fundamental del marco DF, su ingeniero principal afirma que el marco contiene diversidad de forma predeterminada y tiene la capacidad de incorporar la diversidad en el proceso de aprendizaje, lo que permite al usuario personalizarlo completamente a su gusto. Como resultado, en la siguiente sección se analizará cómo utilizar el Deep Forest Framework, anteriormente conocido como GCForest, para abordar la diversidad, que a veces se denomina ambigüedad en la literatura.
Instalación de Deep Forest (DF)
A continuación, suponemos que ya tiene Python instalado porque deep forest es un marco de Python; de lo contrario, consulte el manual de python/pip para obtener información sobre cómo instalarlos. Para instalar el Bosque profundo 21 Framework, siga los pasos que se indican a continuación:
El clasificador DF Cascade Forest utiliza su propio estimador
En el siguiente ejemplo se explica cómo reemplazar el estimador predeterminado por el suyo propio. Esto puede deberse a varias razones, entre ellas: en primer lugar, el deseo de explorar otros clasificadores que no sean el predeterminado para mejorar juntos la diversidad; en segundo lugar, el deseo de explorar con un clasificador bifurcado personalizado de Scikit learn (es decir, tu clasificador personalizado). Supongamos que quiero diseñar un modelo DF que utilice un clasificador RusBoost y un bosque aleatorio como estimadores. Además de lo relacionado con la diversidad, me limitaré a replicar lo que usa el artículo original, pero en lugar de permitir que el marco lo haga de forma predeterminada, usaré un ExtraTreesClassifier directamente desde la implementación de su biblioteca. Buena nota: Esto es totalmente subjetivo; puedes elegir cualquier alumno básico y cualquier clasificador que aumente la diversidad que desees; los elegí al azar arriba únicamente con fines ilustrativos.
(1) Instancie sus estimadores de bosques profundos; si este requiere un estimador adicional, Puede combinarlos de la siguiente manera.
(2) Aplica los estimadores, que están compuestos por el clasificador de tu individuo y algunos que ayuden a la diversidad durante el entrenamiento, y este N tiempo (es decir, aquí hay que elegir N).
Por último, puede realizar la configuración llamando a las funciones habituales de ajuste, predicción y probabilidad y tendrá la posibilidad de mostrar, como de costumbre, el informe de clasificación, la matriz de confusión y/o el mapa de importancia de las características de su modelo mediante una configuración personalizada derivada de la predeterminada.
Discusión/Conclusión
La diversidad no consiste en un conjunto de instrucciones a seguir, como la forma de instalar el software; más bien, se trata de comprender mejor cómo la combinación de dos a N alumnos aumenta la probabilidad de lograr una alta precisión predictiva en la situación actual del mundo real. Tras el lanzamiento de Deep Forest en 2017, este es un tutorial rápido que le ayudará a aprender y comprender cómo utilizar la función de diversidad del marco.
Ahora que sabe cómo realizar el procedimiento de ejecutar a sus propios alumnos con Deep Forest, analicemos sus datos y modelos con Deep Forest y realicemos su diversidad para su caso de aprendizaje automático. Por último, para un análisis más detallado de la diversidad del aprendizaje automático, consulte las referencias y los documentos originales de Deep Forest. Espero que esto haya aclarado por qué la diversidad es importante y lo sencillo que es implementarla utilizando la arquitectura descrita anteriormente. Empieza a usarla ahora y cuéntanos lo que piensas y cómo la cambiarías en la sección de comentarios que aparece a continuación.
Además, ya he publicado un artículo dedicado a esta innovadora técnica de DF aplicada a datos médicos.
Referencias
[1] Z.-H. Zhou y J. Feng, «Deep Forest», preimpresión de arXiv: 1702.08835, 2017.
[2] Z.-H. Zhou y J. Feng, «Deep Forest», National Science Review, vol. 6, núm. 1, págs. 74 a 86, 2019.
[3] Michele L, Provost S, Julien L, Julien L, Julien L, Sauer M, Sauer M, Chaptinel M., Clasificación de los estados de sueño-vigilia con el uso de un novedoso enfoque de aprendizaje profundo. Medio, La organización de Awake (2021).
[4] Zhou ZH. Métodos de conjunto: fundamentos y algoritmos. Boca Raton, Florida: CRC Press, 2012.
[11] Z. Gong, P. Zhong y W. Hu, «La diversidad en el aprendizaje automático», en IEEE Access, vol. 7, págs. 64323—64350, 2019, doi: 10.1109/ACCESS.2019.2917620.