Atualmente, a diversidade é o santo graal da precisão do modelo: a floresta profunda é uma estrutura promissora baseada em camadas de aprendizado profundo, mas sem neurônios e retropropagação. As estruturas revolucionárias de florestas profundas permitem a introdução da diversidade como a ponta do iceberg. O artigo a seguir apresentará a estrutura e a diversidade, além de demonstrar como aplicar seus diversos modelos de conjunto a essa nova estrutura.
Por Simon PROVOST, engenheiro de dados na LittleBigCode

Embora as abordagens em conjunto ofereçam excelentes resultados hoje em dia, Zhi-Hua Zhou E Ji Feng Indique em seu trabalho sobre uma nova metodologia de aprendizado profundo que, quando uma floresta aleatória produz resultados decentes em seus dados, aplique uma floresta profunda e você ficará agradavelmente surpreso. A proposta de Zhi-Hua Zhou e Ji Feng de uma estrutura revolucionária de aprendizado profundo chamada Deep Forest (DF) pode ser considerada um dos eventos mais significativos em aprendizado de máquina em 2017.
O DF emprega várias abordagens baseadas em conjuntos, mais comumente Random Forests (RF) e Stacking, para gerar uma estrutura semelhante à de uma rede neural multicamada, exceto que cada camada é feita de RFs em vez de neurônios. O DF é particularmente favorável ao treinamento porque requer um pequeno número de hiperparâmetros, não requer retropropagação e supera algumas técnicas conhecidas, incluindo redes neurais profundas, quando apenas dados de treinamento em pequena escala estão disponíveis.
O aprimoramento da diversidade é uma técnica que envolve combinar vários alunos “fracos” ou “fracos” ou “fracos”/“eficientes” em um único aluno “forte”, com “fraco” sendo relativo. Como resultado, a teoria de empilhamento deve minimizar tanto o viés quanto a variação e é particularmente eficaz para evitar sobreajuste e variância. Isso ocorre por dois motivos:
- Cada aluno do conjunto terá uma maneira um pouco diferente de mapear recursos e resultados, e a ideia é que, ao combiná-los, uma parte maior da área de pesquisa seja coberta.
- Além disso, considerando o primeiro e o segundo modelos de um conjunto, ambos têm um baixo viés, mas uma alta variância devido ao sobreajuste, eles teoricamente superajustaram regiões separadas do espaço de busca; depois de combiná-las, a variância geral seria reduzida.
Como consequência, juntos aprendendo com foco na diversidade (ou seja, escolha seus alunos com cuidado) Resultará em uma redução na variação geral. Além disso, na prática, isso é comumente adicionado ao conjunto injetando aleatoriedade durante o treinamento.
Como acredito que a diversidade de nossos modelos é o próximo avanço, entre outros, no aprendizado de máquina, aqui está uma descrição mais geral de como o DF inclui o gerenciamento da diversidade e por que ele é fundamental no aprendizado de máquina ou, mais precisamente, nas abordagens conjuntas e no empilhamento.
O artigo a seguir começa com uma visão geral de como o DF funciona, seguido por uma breve explicação de por que a diversidade é importante no DF e, em seguida, uma rápida introdução sobre como aumentar a diversidade com a estrutura do DF (perspectiva prática).
Como funciona a Floresta Profunda em geral?
Como o artigo original afirma isso de forma muito eficaz e sucinta, a explicação a seguir terá um escopo amplo; portanto, para o componente matemático, consulte também os artigos originais. Portanto, analisaremos os componentes de classificação e previsão da arquitetura Deep Forest usando o diagrama abaixo:
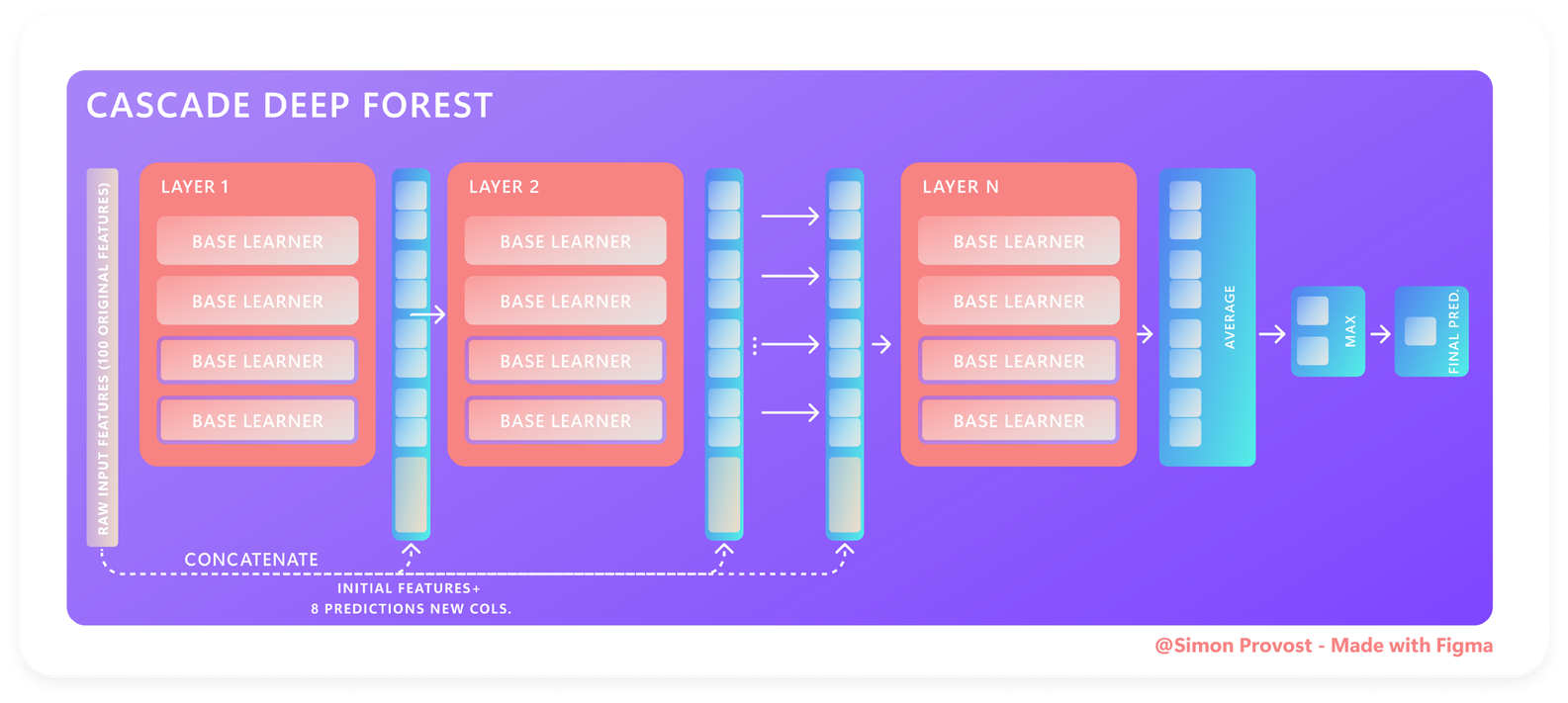
Camada por camada, veja como a Deep Forest Architecture funciona:
- A primeira camada é fornecida com o vetor bruto inicial de características e, em seguida,
Nestimadores previamente configurados são executados, cada um dos quais produz vetor de predição (ou seja, classificação de classe binária: duas saídas, classificação multiclasse:Classe Nsaídas). - Os vetores de predição são concatenados à entrada da segunda camada junto com o vetor bruto inicial, o que naturalmente aumenta a dimensionalidade das características com cada camada subsequente, e assim por diante.
- Por fim, uma média dos resultados de cada camada é determinada;
- E, finalmente, uma função máxima é emitida para obter a previsão final.
Boa nota:Embora os processos anteriores sejam automatizados, a primeira etapa pode ser executada manual ou automaticamente usando a combinação de conjunto padrão especificada pelos designers da estrutura. Para fazer isso manualmente, leia o restante deste artigo para saber como fazer isso.
Como a diversidade é aplicada na Floresta Profunda?
A diversidade é um vasto assunto de estudo, e aqui discutiremos como um engenheiro deve pensar ao selecionar seus alunos básicos (ou seja, algoritmos). Em seguida, concluiremos mostrando como essas três técnicas aplicam a “diversidade”:
- Os primeiros métodos parecem seguir o que a floresta aleatória usa; portanto, baseado em amostras. Essa técnica aplica a diversidade amostra por amostra, o que implica que cada modelo no conjunto pesquisará em uma parte diferente do espaço geral dos dados e, portanto, cobrirá todos os dados com mais eficiência.
- Métodos baseados em hiperparâmetros, que tende a dizer que é melhor otimizar o modelo diretamente em vez de combinar algoritmos precisos, para aumentar a melhoria dos resultados da diversidade; portanto, cada modelo tem uma função objetivo baseada em uma variedade de medidas escolhidas, e os profissionais devem modificar o hiperparâmetro para atingir a função objetivo, de modo que os resultados gerais sejam diversificados em uma perspectiva de hiperparâmetros.
- Finalmente, Métodos baseados em classificação, que organizam pegando uma lista de alunos (diversificados ou não), classificando-os de acordo com os critérios de diversidade desta vez e selecionando o L Um como seu modelo final (por exemplo, o método baseado em cluster envolve traçar os resultados do modelo em um espaço bidimensional e agrupá-los [automaticamente ou não] para extrair apenas aqueles que se correlacionam com o critério fornecido).
Como resultado, dependendo da abordagem usada para selecionar alunos para o conjunto, a diversidade será aplicada de forma diferente, dependendo se a visualização é baseada em amostra, hiperparâmetros ou algoritmo. Finalmente, o DF será usado na perspectiva final quando a média de seus alunos do conjunto for calculada para formar um, momento em que a diversidade será aplicada às descobertas dos alunos que você selecionou anteriormente usando as técnicas resumidas descritas acima.
Por que diversidade em Deep Forest?
Devido ao foco principal da teoria do DF no conjunto e no empilhamento, a diversidade é outro componente chave incluído no pacote. No entanto, por que é um componente tão crítico da estrutura?
O que é o aprendizado em conjunto e os subparadigmas Bagging/Boosting and Stacking?
Do artigo GCForest ao Deep Forest atualizado em 2019: Aprendizagem em conjunto é um paradigma de aprendizado de máquina no qual uma tarefa é resolvida treinando e combinando vários alunos (por exemplo, classificadores). Portanto, entre os métodos de aprendizagem em conjunto, temos:
- Ensacamento que frequentemente considera alunos fracos e homogêneos, os aprende independentemente uns dos outros em paralelo e, em seguida, os combina usando um processo de média determinística;
- Impulsionando Que frequentemente considera alunos fracos e homogêneos, os aprende sequencialmente de uma maneira altamente adaptativa (um modelo básico depende dos anteriores) e os combina usando uma estratégia determinística; e finalmente;
- Empilhamento, por outro lado, frequentemente considera alunos fracos heterogêneos, os aprende em paralelo e os agrega treinando um metamodelo para gerar uma previsão com base na saída de muitos modelos fracos.
Por que a diversidade precisa lidar com o empilhamento?
Devido à maneira heterogênea em que o empilhamento ocorre, a diversidade desempenha um papel fundamental para permitir isso. Conforme mencionado brevemente anteriormente no artigo, a diversidade permite o desenvolvimento de modelos de conjunto robustos; isso também é afirmado no artigo original do DF: “para construir um conjunto forte, os alunos individuais devem ser precisos e diferentes”.
Combinar alunos puramente corretos é frequentemente inferior à combinação de alguns alunos precisos com alguns alunos comparativamente mais fracos, uma vez que a complementaridade tem precedência sobre a precisão pura. No entanto, os cientistas continuam enfrentando o mesmo enigma: “O que é realmente diversidade? 'Essa questão continua sendo o santo graal do campo.
Finalmente, como a diversidade é um componente crítico da estrutura do DF, seu engenheiro-chefe afirma que a estrutura contém diversidade por padrão e tem a capacidade de incorporar diversidade ao processo de aprendizado, permitindo que o usuário a personalize completamente de acordo com sua preferência. Como resultado, a seção a seguir discutirá como usar o Deep Forest Framework, anteriormente conhecido como GCForest, para lidar com a diversidade, que às vezes é chamada de ambigüidade na literatura.
Instalação do Deep Forest (DF)
Presumimos abaixo que você já tenha o Python instalado porque o deep forest é uma estrutura Python; caso contrário, consulte o manual python/pip para obter informações sobre como instalá-los. Para instalar o Floresta Profunda 21 Estrutura, siga as etapas abaixo:
Classificador DF Cascade Forest usando seu próprio estimador
O exemplo a seguir explica como substituir o estimador padrão pelo seu. Isso pode ocorrer por vários motivos, incluindo: primeiro, o desejo de explorar outros classificadores além do padrão para melhorar sua diversidade juntos; segundo, o desejo de explorar com um classificador bifurcado personalizado do Scikit Learn (ou seja, seu classificador personalizado). Suponha que eu queira criar um modelo DF que use um classificador RusBoost e uma floresta aleatória como estimadores. Além disso, sobre diversidade, vou apenas replicar o que o artigo original usa, mas em vez de permitir que a estrutura faça isso por padrão, usarei um ExtraTreesClassifier diretamente da implementação de sua biblioteca. Boa nota: Isso é totalmente subjetivo; você pode escolher qualquer aluno básico e qualquer classificador que aumente a diversidade que desejar; eu os escolhi aleatoriamente acima apenas por uma questão de ilustração.
(1) Instancie seus estimadores de florestas profundas; se este exigir um estimador adicional, Você pode combiná-los da seguinte forma.
(2) Aplique os estimadores compostos por seu classificador de indivíduos acompanhados de alguns que ajudarão na diversidade durante o treinamento, e neste momento N (ou seja, aqui N deve ser escolhido).
Finalmente, você pode realizar sua configuração chamando as funções usuais de predição/previsão de probabilidade de ajuste e fornecerá a possibilidade de exibir, como de costume, o relatório de classificação; a matriz de confusão e/ou o mapa de importâncias de recursos do seu modelo usando uma configuração personalizada derivada da padrão.
Discussão/Conclusão
A diversidade não é um conjunto de instruções a serem seguidas, como instalar software; em vez disso, é uma maior compreensão de como a combinação de dois a N alunos aumenta a probabilidade de alcançar alta precisão preditiva em sua situação atual no mundo real. Como resultado do lançamento do Deep Forest em 2017, aqui está um tutorial rápido para ajudar você a aprender e entender como usar o recurso de diversidade da estrutura.
Agora que você entende como executar o procedimento de executar seus próprios alunos usando o Deep Forest, vamos direcionar seus dados e modelo usando o Deep Forest, bem como aprimorar sua diversidade para fins de seu caso de aprendizado de máquina. Por fim, para um exame mais aprofundado da diversidade do aprendizado de máquina, consulte as referências e os artigos originais sobre florestas profundas. Espero que isso tenha esclarecido por que a diversidade é importante e como é simples implementá-la usando a arquitetura descrita acima. Comece a usá-lo agora e diga-nos o que você acha e como você o mudaria na seção de comentários abaixo.
Além disso, já publiquei um artigo dedicado a essa técnica inovadora de DF aplicada a dados médicos.
Referências
[1] Z.-H. Zhou e J. Feng, “Deep Forest”, pré-impressão arXiv: 1702.08835, 2017.
[2] Z.-H. Zhou e J. Feng, “Floresta profunda”, National Science Review, vol. 6, nº 1, pp. 74—86, 2019.
[3] Michele L, Provost S, Julien L, Julien L, Julien L, Sauer M, Sauer M, Chaptinel M., Classificação dos estados de sono-vigília com o uso de uma nova abordagem de aprendizado profundo. Médio, Organização da Awake (2021).
[4] Zhou ZH. Métodos de conjunto: fundamentos e algoritmos. Boca Raton, Flórida: CRC Press, 2012.
[11] Z. Gong, P. Zhong e W. Hu, “Diversidade no aprendizado de máquina”, no IEEE Access, vol. 7, pp. 64323—64350, 2019, doi: 10.1109/ACCESS.2019.2917620.