Why does the Public Prosecutor's Office exist?
The Parquet format was created to meet the needs of frequent queries on Hadoop (successor to Trevni). The columnar format such as Parquet solves some limitations of so-called “traditional” data formats such as CSV. As a column-based storage format, Parquet allows for more efficient reading of data when only specific columns are targeted, which optimizes the performance of analytical queries.
Line Format vs. Column Format: What's the difference?
— Line format such as CSV, requires the complete reading of each row to access a specific column, causing time and performance losses.
— Column format like Parquet allows direct access to targeted columns, thus reducing the volume of scanned data and improving processing speed.
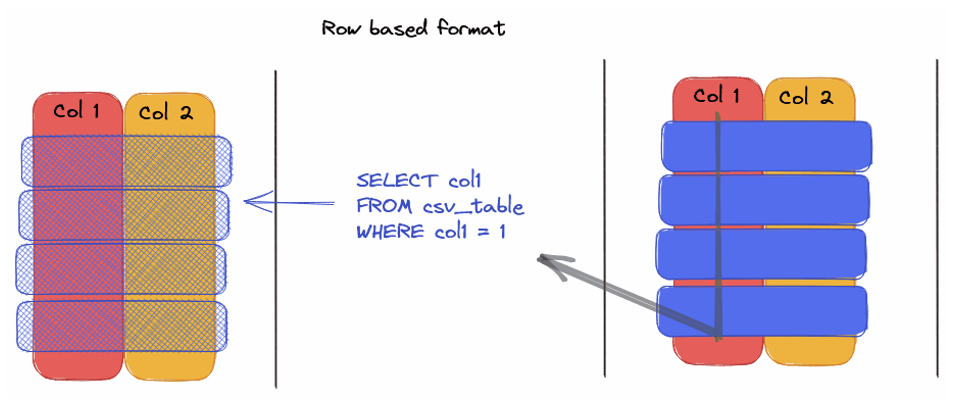
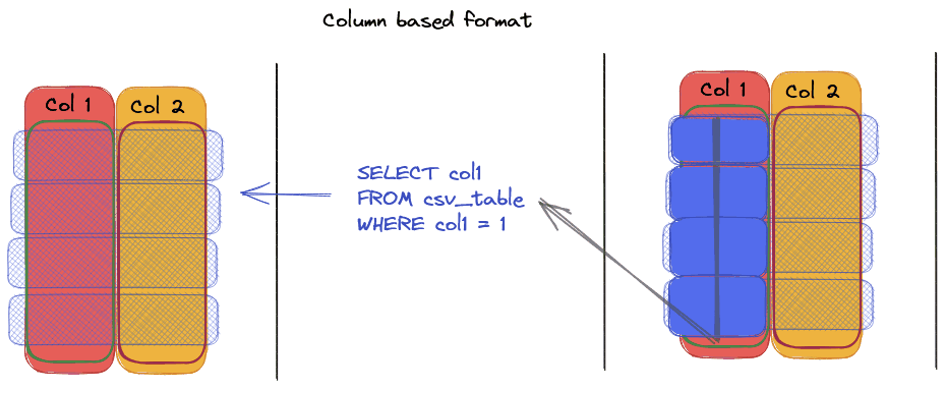
The advantages of Parquet compared to CSV
— Data typing: Parquet stores data types directly in metadata, making it easy to manage types
— Data compression: Supports multiple algorithms (Snappy, Gzip, etc.), offering considerable space savings (up to 87% reduction in storage)
— Data Encoding: Use techniques like Dictionary Encoding to optimize the storage of repetitive values.
— Parallel read/write: Compatible with distributed systems like Apache Spark, allowing faster processing of massive files.
— Enriched metadata: Parquet stores advanced statistics allowing optimizations during queries.

Real use cases with AWS Athena

During comparative tests on AWS Athena, Parquet demonstrated:
— Space saving: A 1 TB dataset in CSV reduced to 130 GB in Parquet, i.e. 87% gain
— Speed improvement: SQL query increased from 236 seconds (CSV) to 6.78 seconds (Parquet), 34 x faster
— Cost reduction: From €5.75 in CSV to €0.01 in Parquet thanks to the reduction of scanned data. A ~ 99% discount.
Source: https://www.linkedin.com/pulse/difference-between-parquet-csv-emad-yowakim/
Pro Tip: Consider aggregating/coallesce to minimize the number of files that are not too big (< 1GB)
The limits of the Parquet format in Machine Learning
— Not suitable for unstructured data: Parquet is not ideal for storing ML models or unstructured data (images, videos)
— Problems with massive writing: Requires loading all data into RAM before writing, which can be limiting for large models.

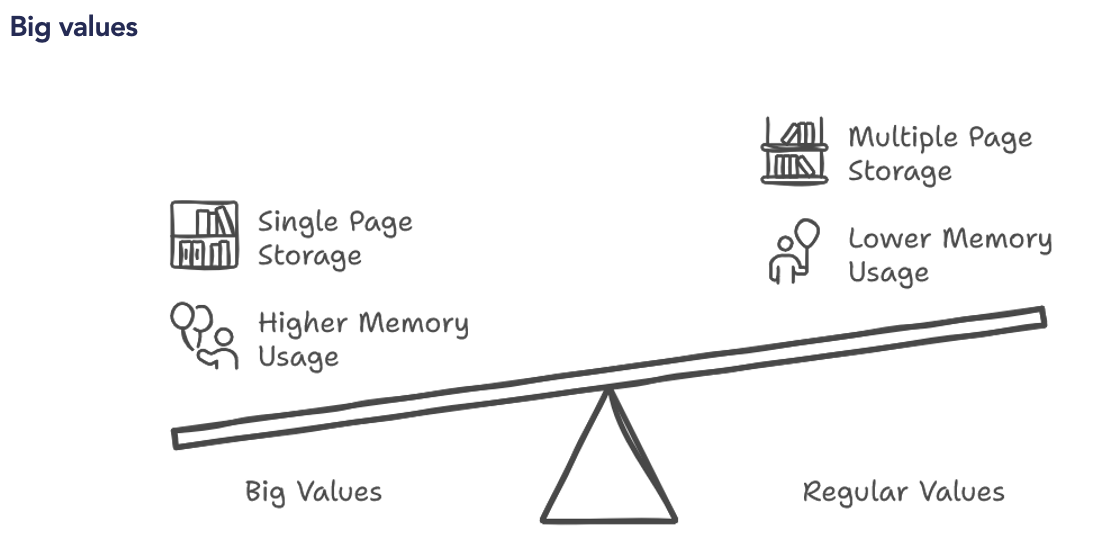
Modern Alternatives: Lance and Nimble
— Launch (LanceDB): Offers an improved version of Parquet, eliminating row groups for up to 2000x better reading performance.

— Nimble (Meta): Optimizes the ORC format (alternative to Parquet) by centralizing the metadata (footers instead of headers in Parquet) and by changing the way this metadata is defined, thus offering gains in access speed.

The Parquet format is an essential choice for storing analytical data, especially thanks to its advantages in terms of compression, data typing, and SQL performance. However, for use cases in machine learning or on unstructured data, new alternatives such as Lance and Nimble are emerging, offering better performance.