Por que existe o Ministério Público?
O formato Parquet foi criado para atender às necessidades de consultas frequentes no Hadoop (sucessor do Trevni). O formato colunar, como o Parquet, resolve algumas limitações dos chamados formatos de dados “tradicionais”, como CSV. Como formato de armazenamento baseado em colunas, o Parquet permite uma leitura mais eficiente dos dados quando somente colunas específicas são segmentadas, o que otimiza o desempenho das consultas analíticas.
Formato de linha versus formato de coluna: qual é a diferença?
— O formato de linha, como CSV, exige a leitura completa de cada linha para acessar uma coluna específica, causando perdas de tempo e desempenho.
— O formato de coluna, como o Parquet, permite acesso direto às colunas específicas, reduzindo assim o volume de dados digitalizados e melhorando a velocidade de processamento.
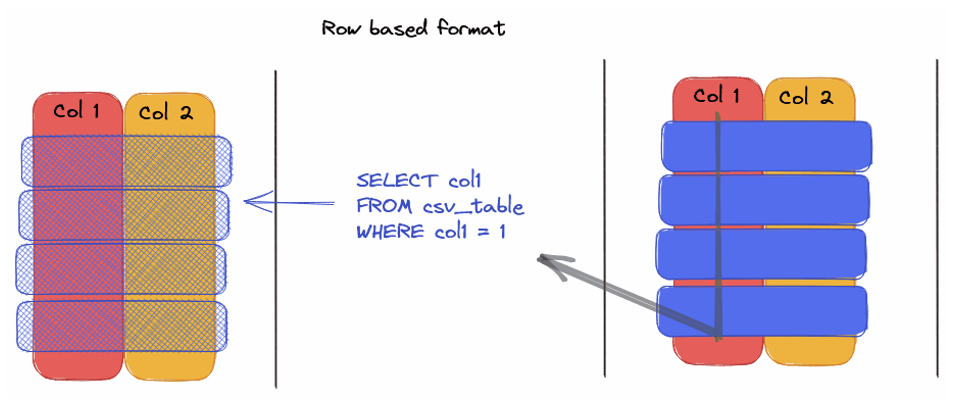
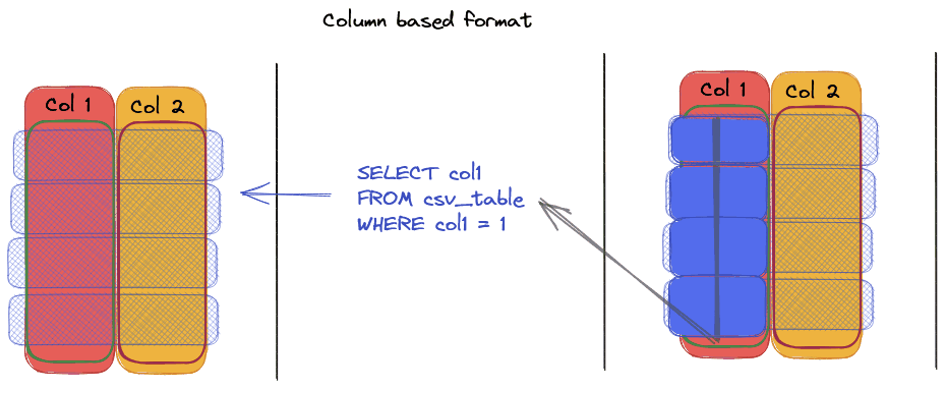
As vantagens do Parquet em comparação com o CSV
— Digitação de dados: o Parquet armazena os tipos de dados diretamente nos metadados, facilitando o gerenciamento de tipos
— Compressão de dados: suporta vários algoritmos (Snappy, Gzip, etc.), oferecendo considerável economia de espaço (redução de até 87% no armazenamento)
— Codificação de dados: use técnicas como a codificação de dicionário para otimizar o armazenamento de valores repetitivos.
— Leitura/gravação paralela: compatível com sistemas distribuídos como o Apache Spark, permitindo um processamento mais rápido de arquivos massivos.
— Metadados enriquecidos: o Parquet armazena estatísticas avançadas, permitindo otimizações durante as consultas.

Casos de uso reais com o AWS Athena

Durante testes comparativos no AWS Athena, a Parquet demonstrou:
— Economia de espaço: um conjunto de dados de 1 TB em CSV reduzido para 130 GB no Parquet, ou seja, ganho de 87%
— Melhoria da velocidade: a consulta SQL aumentou de 236 segundos (CSV) para 6,78 segundos (Parquet), 34 vezes mais rápido
— Redução de custos: de 5,75€ em CSV a 0,01€ em Parquet, graças à redução dos dados digitalizados. Um desconto de ~ 99%.
Fonte: https://www.linkedin.com/pulse/difference-between-parquet-csv-emad-yowakim/
Dica profissional: considere agregar/unir para minimizar o número de arquivos que não são muito grandes (< 1 GB)
Os limites do formato Parquet no aprendizado de máquina
— Não é adequado para dados não estruturados: o Parquet não é ideal para armazenar modelos de ML ou dados não estruturados (imagens, vídeos)
— Problemas com a gravação em massa: requer o carregamento de todos os dados na RAM antes da gravação, o que pode ser limitante para modelos grandes.

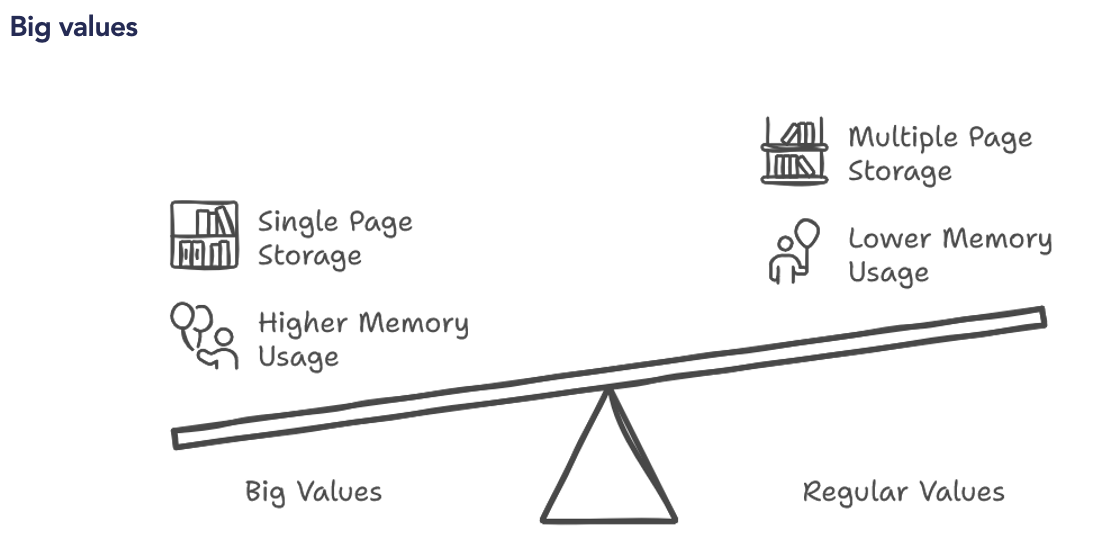
Alternativas modernas: Lance e Nimble
— Launch (LanceDB): oferece uma versão aprimorada do Parquet, eliminando grupos de linhas para um desempenho de leitura até 2.000 vezes melhor.

— Nimble (Meta): otimiza o formato ORC (alternativo ao Parquet) centralizando os metadados (rodapés em vez de cabeçalhos no Parquet) e alterando a forma como esses metadados são definidos, oferecendo ganhos na velocidade de acesso.

O formato Parquet é uma escolha essencial para armazenar dados analíticos, especialmente graças às suas vantagens em termos de compressão, digitação de dados e desempenho de SQL. No entanto, para casos de uso em aprendizado de máquina ou em dados não estruturados, novas alternativas, como Lance e Nimble, estão surgindo, oferecendo melhor desempenho.